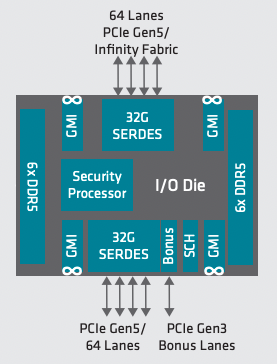
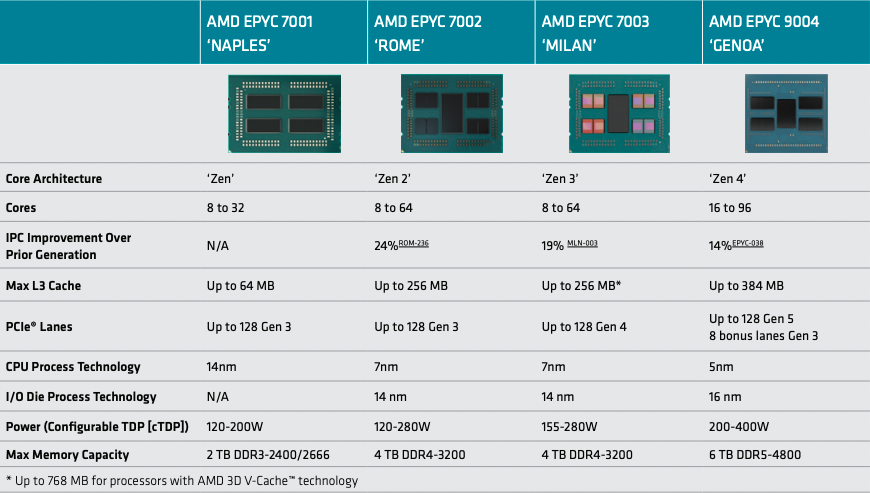
Today’s data center has numerous challenges: provisioning hardware and cloud workloads, balancing the needs of performance-intensive applications across compute, storage and network resources, and having a consistent monitoring and analytics framework to feed intelligent systems management. Plus, you may have the need to deploy or re-deploy all these resources as needs shift, moment to moment.
Supermicro has created its own tool to assist with these decisions to monitor and manage this broad IT portfolio, called the SuperCloud Composer (SCC). It combines a standardized web-based interface using an Open Distributed Infrastructure Management interface with a unified dashboard based on the RedFish message bus and service agents.
SCC can track the various resources and assign them to different pools with its own predictive analytics and telemetry. It delivers a single intelligent management solution that covers both existing on-premises IT equipment as well as a more software-defined cloud collection. Additional details can be found in this SuperCloud Composer white paper.
SuperCloud Composer makes the use of a cluster-level PCIe network using the FabreX software from GigaIO Networks. It has the capability to flexibly scale up and out storage systems while using the lowest latency paths available.
It also supports Weka.IO cluster members, which can be deployed across multiple systems simultaneously. See our story The Perfect Combination: The Weka Next-Gen File System, Supermicro A+ Servers and AMD EPYC™ CPUs.
SCC can create automated installation playbooks in Ansible, including a software boot image repository that can quickly deploy new images across the server infrastructure. It has a fast-deploy feature that allows a new image to be deployed within seconds.
SuperCloud Composer offers a robust analytics engine that collects historical and up-to-date analytics stored in an indexed database within its framework. This data can produce a variety of charts, graphs and tables so that users can better visualize what is happening with their server resources. Each end-user is provided with analytic capable charting represented by IOPS, network, telemetry, thermal, power, composed node status, storage allocation and system status.
Last but not least, SCC also has both network provisioning and storage fabric provisioning features where build plans are pushed to data or fabric switches either as single-threaded or multithreaded operations, such that multiple switches can be updated simultaneously by shared or unique build plan templates.
For more information, watch this short SCC explainer video. Or schedule an online demo of SCC and request a free 90-day trial of the software.